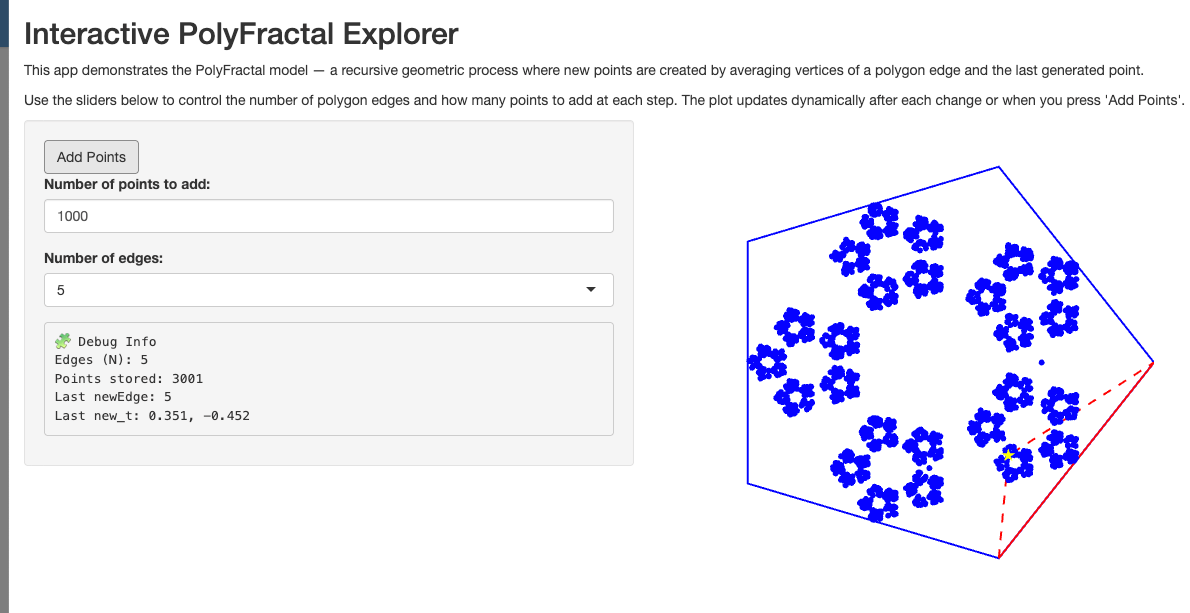
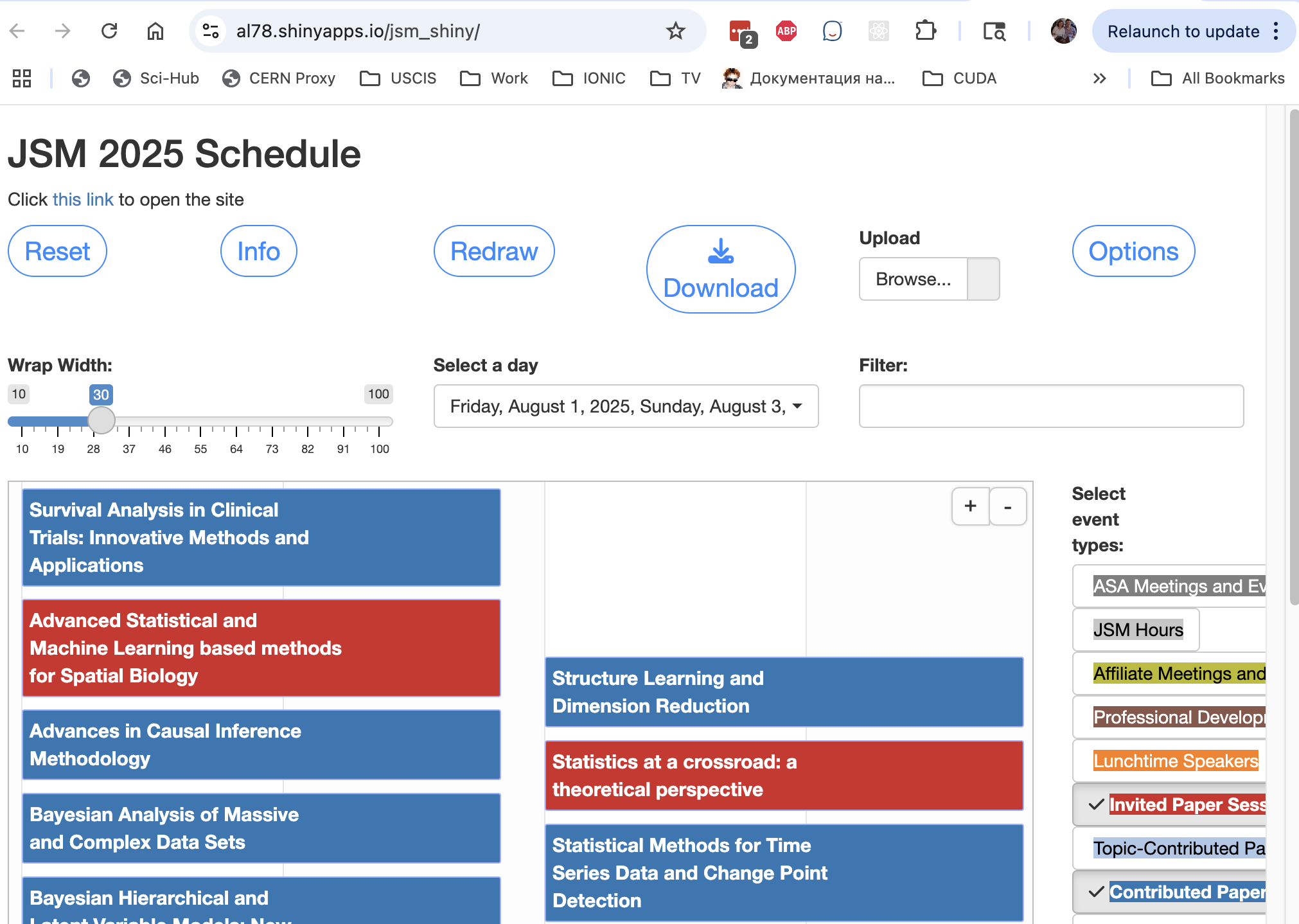
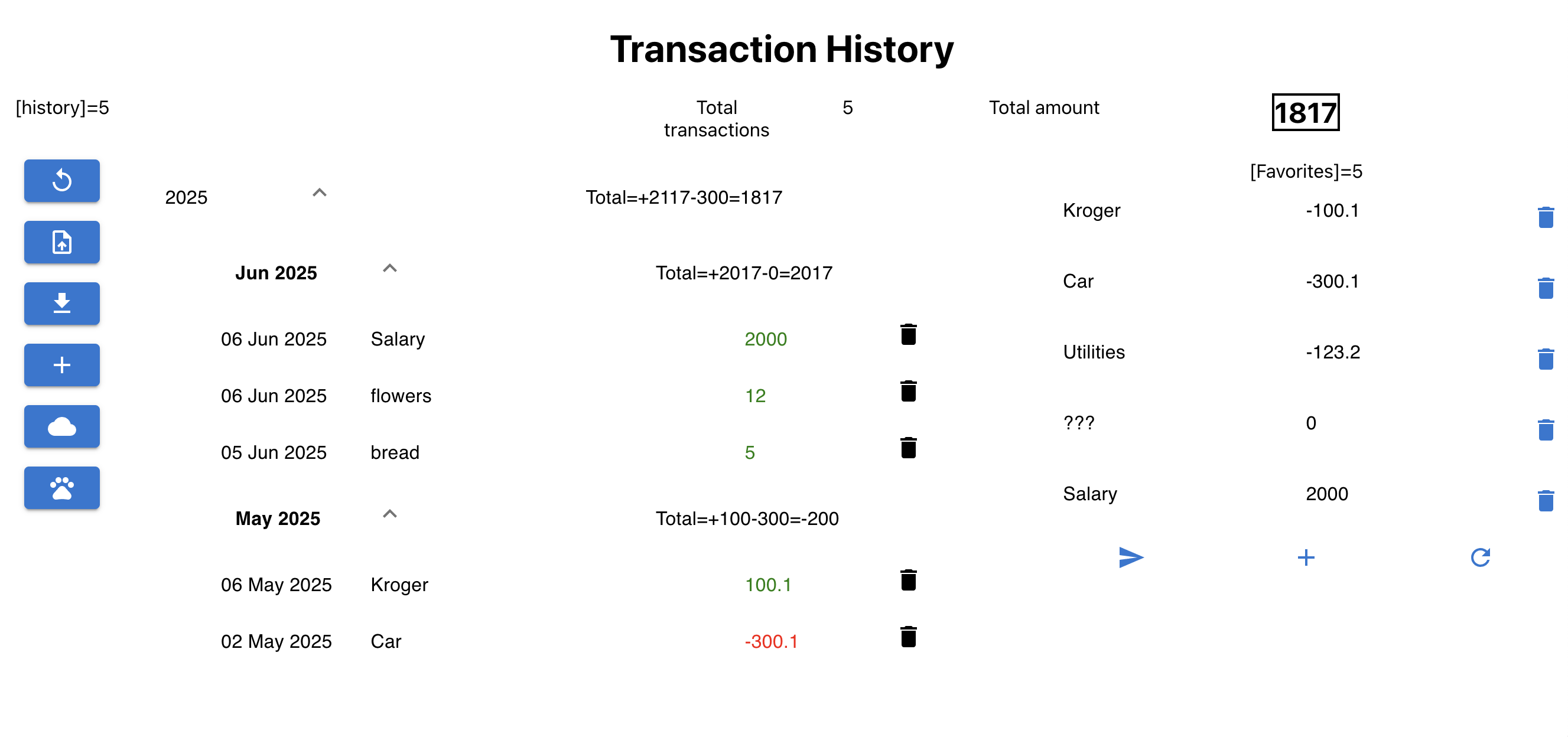
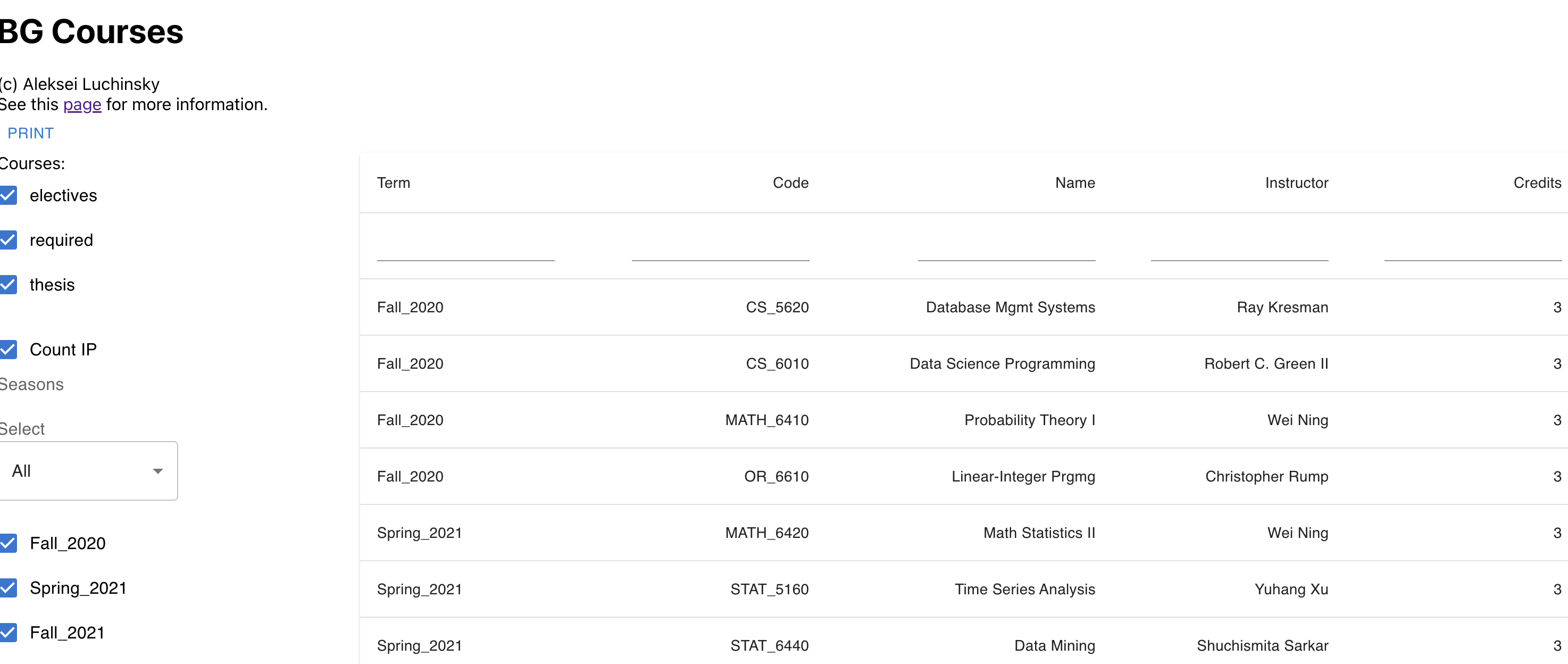
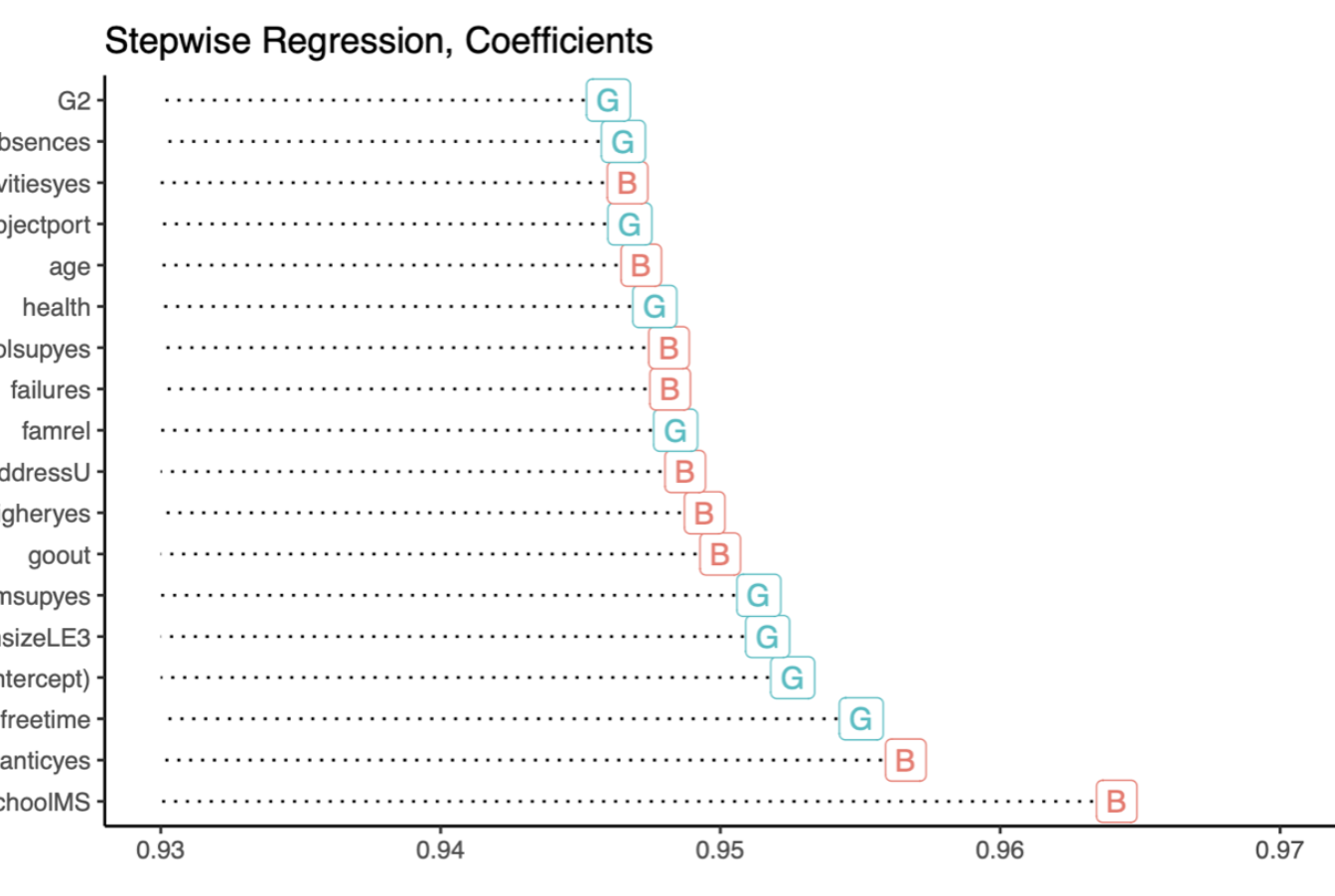
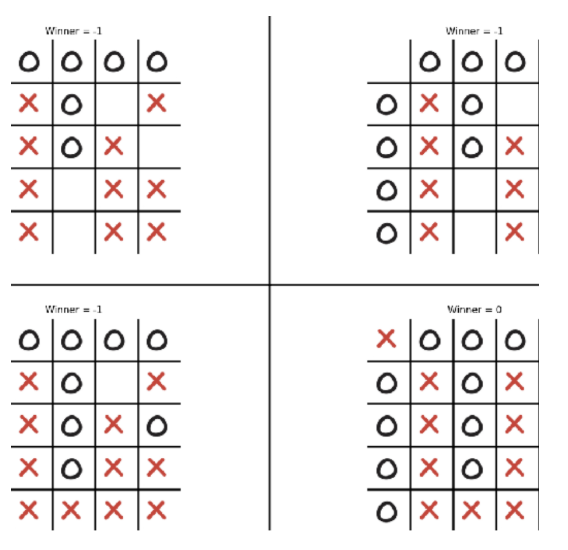
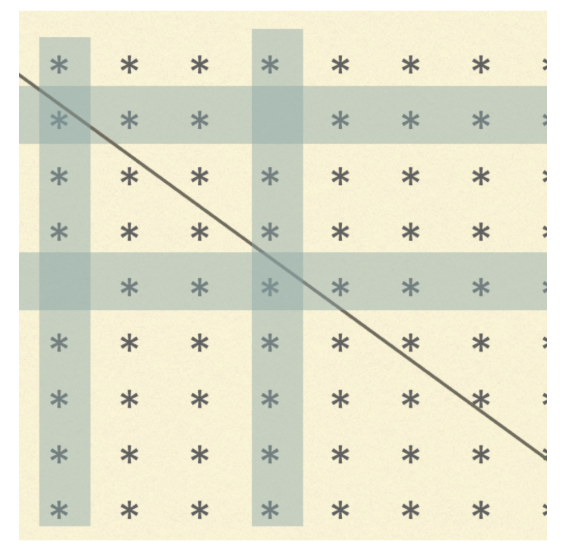
You can download my CV in PDF format
here.
Education
| Jan 2022 — May 2025 |
Ph.D in Data Science |
|
Bowling Green State University |
|
GPA: 4.0 |
| Sep 2020 — Dec 2021 |
MS in Data Science |
|
Bowling Green State University |
|
GPA: 3.85 |
| Sep 1995 — Aug 2007 |
MS, Ph.D in Theoretical Physics |
|
Moscow Institute o Physics and Technology, Russia |
|
GPA: 3.9 |
Work Experience
| Aug 2023 — May 2025 |
Data Analyst
Student Success Analysis Technologies (Bowling Green State University, Bowling Green, OH)
- Designed and implemented machine learning models for predictive analytics.
- Developed dashboards and web applications for data visualization and reporting.
- Conducted statistical analysis to optimize university performance metrics.
- Designed and implemented machine learning models for predictive analytics.
- Developed dashboards and web applications for data visualization and reporting.
- Conducted statistical analysis to optimize university performance metrics
|
| Aug 2022 — May 2023 |
Adjunct Instructor
Bowling Green State University (Bowling Green, OH)
- Fall 2022: Physics
- Spring 2023: Business Statistics
|
| Apr 2021 — Dec 2021 |
Software Developer
Senico Corp (Bowling Green, OH)
- Created web application for hotel business KPI analysis.
|
| Aug 2019 — May 2020 |
Adjunct Instructor
Bowling Green State University (Bowling Green, OH)
- Spring 2020: Business Calculus
- Fall 2019: Calculus, Discrete Math
|
Skills
| Mathematics |
Statistics |
Teaching |
| C++, R, Python |
Software Development |
Problem-solving abilities |
| Modeling |
Data Analysis |
Machine Learning |
| Time Series |
Topological Data Analysis |
Teamwork |
Certificates
Data Science
Kit C Chan, Umar Islambekov, Alexey Luchinsky, Rebecca Sander, "A Computationally Efficient Framework for Vector Representation of Persistence Diagrams", Journal of Machine Learning Research, 23, 1-33, 2020, JMLR
Aleksei Luchinsky, Umar Islambekov, "Vectorization of Persistence Diagrams for Topological Data Analysis in R and Python Using TDAvec Package", arXiv:2411.17340, arXiv
Umar Islambekov, Aleksei Luchinsky, "TDAvec: Computing Vector Summaries of Persistence Diagrams for Topological Data Analysis in R and Python", JOSS, DOI:10.21105/joss.08532
You can also find list of my High Energy Physics publications following the link
Google Scholar